
Cred că astăzi nu poți vorbi despre supercomputere fără să o raportezi la Linux, și este că, în ciuda faptului că Linux a fost conceput la început pentru a fi sectorul computerelor personale, se poate spune că a dominat toate sectoarele, cu excepția faptului că așa cum vom vedea mai târziu cu câteva statistici interesante. În plus, este un sector în care nu există prea multe informații publicate în spaniolă care să fie accesibile tuturor.

Pe de altă parte, am reușit să verific asta lumea supercomputerelor sau interesele de supercomputere, dar în general este destul de necunoscut pentru mulți dintre utilizatori. De aceea mi-am luat timp să creez și să public acest mega post despre supercomputere care sper să vă învețe foarte mult toate secretele acestui „misterios” și că atunci când veți termina de citit tot acest text nu va mai avea secrete pentru tu ...
Mai mult decât un articol sau un mega post, va fi un fel de Wiki teoretic-practic despre supercomputere pe care îl puteți consulta oricând. Acesta este scopul, ca acest articol LxA să fie un punct de cotitură, un înainte și după. Îl voi lua? Hai să verificăm ...
Introducere în supercomputere
Pentru a clarifica de la început, computerele pe care le avem în casele noastre sunt printre cele mai puternice care există. Ceea ce vreau să spun prin aceasta este că nu există un microprocesor mult mai puternic decât cele pe care le folosim zilnic. Cheia supercomputerelor nu se află în microprocesoare ultra-puternice sau în componente foarte exotice și diferite de cele pe care le folosim zilnic în casele noastre, cheia supercomputării este paralelismul.
Permiteți-mi să vă explic, băncile de memorie RAM, hard disk-urile, microprocesoarele, plăcile de bază etc. unui supercomputer sunt probabil mai asemănătoare decât vă imaginați cu cele pe care le utilizați în acest moment sau pe care le aveți acasă. Numai în cazul supercomputerelor, acestea sunt grupate în sute sau mii pentru a aduna puterea fiecăruia dintre aceste „computere” independente și astfel compune o mașină grozavă care funcționează ca un singur sistem.
Vorbesc despre calcul paralel, Da. O paradigmă care permite crearea de supercalculatoare sau ceea ce știm ca HPC (High-Performance Computing) sau calcul de înaltă performanță. Ce vreau să spun este că dacă aveți acasă un AMD Ryzen 7, cu 16 GB RAM, o placă de rețea și un hard disk de 8 TB, ... imaginați-vă ce s-ar întâmpla dacă ați înmulți acest lucru cu 1000 și l-ați funcționa ca dacă ar fi doar un PC. Ar fi 1000 Ryzen care rulează în paralel, 16 TB RAM și 8 PB de stocare. Wow !! Acest lucru începe deja să semene mai mult cu un supercomputer, nu?
Îmi pare rău dacă crezi unul o introducere foarte simplă și o definiție oarecum lipicioasă, dar a fost intenționat. Pentru că vreau chiar și utilizatorul cel mai puțin cunoscător și cu experiență să înțeleagă ideea acestei paradigme, altfel nu vor înțelege restul acestui ghid. Vreau să rămâi cu ideea asta, deoarece dacă o prinzi, vei vedea cum acele mașini mari și ciudate care ocupă suprafețe mari nu ți se vor părea atât de ciudate ...
Ce sunt supercomputerele?
În secțiunea anterioară am introdus termenii paralelism și HPC, bine. Pentru a crea un supercomputer, adică un computer cu aceste capacități HPC, paralelismul este necesar așa cum am precizat. Prin definitie, supercomputerele sunt acele mașini ale căror capacități de un fel sunt mult superiori la cel al unui computer comun pe care îl putem avea acasă.
În general, aproape toate capacitățile unui supercomputer sunt mult superioare unui PC, dar pot atrage atenția în special puterea de calcul care se datorează nucleelor sau unităților de procesare, Memorie RAM disponibile pentru astfel de unități de procesare și, într-o măsură mai mică, capacitate de stocare, deoarece, în general, primele două sunt mai importante pentru aplicațiile normale care sunt date acestui tip de mașină. Deși este adevărat că pot exista unele mașini mari care necesită mult mai mult spațiu de stocare și lățime de bandă decât puterea de calcul sau RAM, acesta este cazul serverelor de stocare ...
Istoria supercomputerelor:
Poate că unul dintre primele supercalculatoare, sau, după cum istoricii o clasifică așa, a fost mașina construită în anii 60 de către Sperry rand pentru Marina Statelor Unite. Apoi, va veni un moment în care IBM era marele rege cu mașini precum IBM 7030 și multe altele. De asemenea, Atlasul Universității din Manchester și Ferranti, la începutul anilor 60, ca competiție europeană pentru mașinile americane. Mașini care începeau deja să utilizeze tranzistoare de germaniu ca înlocuitor pentru vechile tuburi de vid (nu circuite integrate) și memorii magnetice pentru compoziția lor, dar care erau încă foarte primitive.
Apoi va veni o altă eră în care a intrat o altă mare, CDC, cu CDC 6600 proiectat de un vechi cunoscut care ar numi ulterior o companie importantă care este astăzi lider în acest sector. Vorbesc despre Seymour cray. Mașina pe care a proiectat-o a fost finalizată în 1964 și a fost una dintre primele care a utilizat tranzistoare cu siliciu. Viteza adusă de noua tehnologie de siliciu și arhitectura proiectată de Cray au făcut ca mașina să fie de până la 10 ori mai rapidă decât concurența, vândând 100 dintre ele pentru 8.000.000 de dolari fiecare.
Cray dejaría CDC (Control Data Corporation) en 1972 para formar la compañía líder que os he comentado, se trata de la Cray Research, creando el Cary-1 de 80 Mhz y uno de los primeros CPUs de 64-bit en 1976, convirtiendose en la supercomputadora más exitosa de la época y que podéis ver en la imagen principal de este apartado en la fotografía en blanco y negro. La Cray-2 (1985) seguiría el exitoso camino de la primera, con 8 CPUs, refrigeración líquida y marcando el camino de las modernas supercomputadoras en muchos sentidos. Aunque el rendimiento era de 1,9 GFLOPS.
O sumă care acum poate părea aproape ridicolă, având în vedere că smartphone-ul pe care îl aveți acum în buzunar îl depășește cu aceste supercalculatoare ale vremii. De exemplu, a SoC Snapdragon 835 sau Exynox 8895 de la Qualcomm sau Samsung respectiv, are o putere de aproximativ 13,4 GFLOPS, adică de aproape 10 ori mai mult decât Cray-2 și de aproximativ 100 de ori mai mare decât Cray-1. Acele mașini gigantice nu ajung la talpa pantofilor dvs. la un obiect la fel de mic și ușor ca cel pe care îl aveți acum în mâini. Ceea ce aș vrea să cred că, în câteva decenii, putem avea dispozitive la fel de puternice sau mai multe ca supercomputerele actuale, dar reduse la dimensiuni mici ale carcasei.
Continuând cu povestea, după acest timp a venit era proiectelor masiv paralele, adică, costurile mai ieftine ale producției de jetoane și îmbunătățirile interconectărilor au făcut posibil ca în loc de mașini sofisticate, supercomputerele să poată fi construite prin alăturarea a sute sau mii de jetoane destul de asemănătoare cu cele pe care le avem în echipamentele noastre de acasă, cum ar fi eu comentat anterior. De fapt, în anii 1970 a existat o mașină care folosea acest nou design masiv și care depășea cu mult Cray-1 (250 MFLOPS), adică ILLIAC IV, cu 256 de microprocesoare care atingeau 1 GFLOPS, deși avea unele probleme de proiectare și nu a fost finalizat, a fost implementat doar un design cu 64 de microprocesoare.
Un supercomputer grafic LINKS-1 de la Universitatea Osaka ar fi un alt dintre aceste aparate masiv paralele, cu 257 microprocesoare Zilog Z8001 și 257 FPU Intel iAPX 86/20, obținând performanțe bune pentru acea vreme și putând reda grafică 3D realistă, cu 1.7 GFLOPS. Și încetul cu încetul ar veni mașini din ce în ce mai puternice, trecând de la sute de microprocesoare la mii ca cele actuale ...
În Spania avem unul dintre cele mai puternice supercalculatoare din Europa și, de asemenea, unul dintre cele mai puternice din lume, creat de IBM și numit Ameţeală, situat în Bacelona și aparținând rețelei de supercomputere spaniole alcătuită din mai multe dintre ele, precum Picasso de la Universitatea din Malaga, care se hrănește cu materialul aruncat în actualizările pe care MareNostrum le primește periodic. De fapt, MareNostrum este o mașină care îl fascinează pe autorul Dan Brown și care a fost ales ca cel mai frumos centru de date (amestecând o arhitectură a unei vechi mănăstiri cu cea mai înaltă tehnologie), după cum puteți vedea în imaginea principală a acestui articol.
Performanță maximă 11.15 PFLOPS Microprocesoare 165.888 Intel Xeon Platinum RAM 390 TB Roșu Omnipat proiectant IBM Platformă SUSE Linux
Caracteristici supercomputer:
Deși mulți autori se separă (în opinia mea eronat) servere supercomputer Și chiar mainframe, conform definiției pe care v-am făcut-o de supercomputer, serverele ar putea fi perfect cuprinse ca supercomputer, deoarece nu sunt altceva decât computere cu capacități mult superioare computerelor normale, doar că sunt dedicate oferirii unui anumit tip de serviciu în cadrul o rețea ... Singurul lucru care trebuie diferențiat este că, în funcție de ceea ce este destinat mașinii, vom avea capabilități pe care le dorim deasupra celorlalte sau a altora.
De exemplu, pentru un server destinat datelor, cum ar fi un serviciu de stocare în cloud, ceea ce ne interesează este că are o capacitate de stocare brutală. În timp ce pentru un mainframe destinat procesării tranzacțiilor și operațiunilor bancare, cel mai important lucru va fi puterea sa de calcul. Dar insist, ambele sunt supercalculatoare. Cu toate acestea, să vedem câteva principalele caracteristici care ne interesează de la un supercomputer / mainframe / server:
Securitate : Dacă este un supercomputer care este izolat, adică deconectat de la Internet, poate că trebuie implementate măsuri de securitate perimetrale, dar securitatea ca atare în cadrul sistemului în sine nu este la fel de importantă ca un server conectat și la care sunt a conectat mulți clienți sau poate fi ținta atacurilor în timp ce este conectat la Internet. Dar, fie într-un caz sau altul, vor exista întotdeauna măsuri de securitate.
: Dacă este un supercomputer care este izolat, adică deconectat de la Internet, poate că trebuie implementate măsuri de securitate perimetrale, dar securitatea ca atare în cadrul sistemului în sine nu este la fel de importantă ca un server conectat și la care sunt a conectat mulți clienți sau poate fi ținta atacurilor în timp ce este conectat la Internet. Dar, fie într-un caz sau altul, vor exista întotdeauna măsuri de securitate. Valabilitate ridicată : un server sau un supercomputer trebuie să funcționeze corect și să reducă la minimum posibilele probleme hardware sau software, deoarece oprirea acestuia poate fi fatală pentru scopurile pentru care a fost construit și, în 100% din cazuri, un computer defect va însemna pierderea unor sume mari de bani. De aceea se iau măsuri în sistemele de operare pentru a reduce repornirile necesare și robuste (UNIX / Linux), sursele de alimentare alternative (UPS) în caz de întrerupere, redundanța sistemelor în cazul în care nu se reușește că există o replică care nu afectează prea mult pentru performanța generală, tehnici de împrejmuire pentru a izola un nod, astfel încât să nu îi afecteze pe ceilalți și să poată fi înlocuit la cald, fără a afecta funcționarea restului, toleranță la erori cu sisteme precum RAID pe hard disk, memorie ECC, evita Split-brain , aveți un DRP (Disaster Recovery Plan) pentru a acționa în caz de probleme etc. Și, de asemenea, dorim ca fiabilitatea să fie maximă, precum și durata de viață utilă, iar următorii parametri sunt întotdeauna cei mai mici sau cei mai mari în funcție de care este: MTTF (Timpul mediu până la eșec): este timpul mediu până la eșecuri, adică măsoară timpul mediu în care un sistem este capabil să funcționeze fără întrerupere până când are un eșec. Prin urmare, cu cât este mai mare cu atât mai bine. MTBF (Timpul mediu între defecțiuni): este timpul mediu dintre defecțiuni, adică este de asemenea important ca acesta să fie mai mare, deoarece nu dorim ca defecțiunile să fie foarte consecutive sau altfel fiabilitatea echipamentului va fi proastă. MTTR (Timpul mediu de reparare): timpul mediu de reparare, adică este mentenabilitate. Vrem să fie mai scăzut, astfel încât sistemul să nu mai funcționeze mult timp.
: un server sau un supercomputer trebuie să funcționeze corect și să reducă la minimum posibilele probleme hardware sau software, deoarece oprirea acestuia poate fi fatală pentru scopurile pentru care a fost construit și, în 100% din cazuri, un computer defect va însemna pierderea unor sume mari de bani. De aceea se iau măsuri în sistemele de operare pentru a reduce repornirile necesare și robuste (UNIX / Linux), sursele de alimentare alternative (UPS) în caz de întrerupere, redundanța sistemelor în cazul în care nu se reușește că există o replică care nu afectează prea mult pentru performanța generală, tehnici de împrejmuire pentru a izola un nod, astfel încât să nu îi afecteze pe ceilalți și să poată fi înlocuit la cald, fără a afecta funcționarea restului, toleranță la erori cu sisteme precum RAID pe hard disk, memorie ECC, evita Split-brain , aveți un DRP (Disaster Recovery Plan) pentru a acționa în caz de probleme etc. Și, de asemenea, dorim ca fiabilitatea să fie maximă, precum și durata de viață utilă, iar următorii parametri sunt întotdeauna cei mai mici sau cei mai mari în funcție de care este: Performanță ridicată și echilibrare a sarcinii: Acest lucru este deosebit de important atunci când vine vorba de un serviciu cloud care trebuie să ruleze aplicații pentru clienții săi, pe supercalculatoare sau mainframe pentru calcule matematice sau simulări științifice etc. Se realizează prin creșterea cantității de memorie RAM și a cantității și / sau performanței microprocesoarelor. În plus, trebuie să avem o bună echilibrare a sarcinii, care depinde de gestionarea proceselor pe care le facem, deci nu vom supraîncărca unele noduri mai mult decât altele, dar vom echilibra volumul de lucru pe întregul supercomputer în mod egal sau în cel mai omogen posibil.
Acest lucru este deosebit de important atunci când vine vorba de un serviciu cloud care trebuie să ruleze aplicații pentru clienții săi, pe supercalculatoare sau mainframe pentru calcule matematice sau simulări științifice etc. Se realizează prin creșterea cantității de memorie RAM și a cantității și / sau performanței microprocesoarelor. În plus, trebuie să avem o bună echilibrare a sarcinii, care depinde de gestionarea proceselor pe care le facem, deci nu vom supraîncărca unele noduri mai mult decât altele, dar vom echilibra volumul de lucru pe întregul supercomputer în mod egal sau în cel mai omogen posibil. Scalaritate : capacitatea software-ului și hardware-ului de a se adapta fără limitări la schimbarea configurației sau a dimensiunii. Acest tip de mașină trebuie să fie flexibilă atunci când vine vorba de extinderea capacității de calcul sau a capacității de memorie etc., dacă ar eșua fără a fi nevoie să dobândească un nou supercomputer.
: capacitatea software-ului și hardware-ului de a se adapta fără limitări la schimbarea configurației sau a dimensiunii. Acest tip de mașină trebuie să fie flexibilă atunci când vine vorba de extinderea capacității de calcul sau a capacității de memorie etc., dacă ar eșua fără a fi nevoie să dobândească un nou supercomputer. Coaste: Acest lucru nu depinde doar de costul mașinii în sine și de întreținere, care poate ajunge cu ușurință în milioane, dar depinde și de consumul mașinii, care este de obicei măsurat în MW (megawați) și de costul sistemelor de răcire, care este, de asemenea, ridicat prin cantitatea de căldură pe care o generează. De exemplu, dacă luăm ca exemplu centrul de date Facebook unde are serverul în care este găzduit serviciul său, avem miliarde de cheltuieli, aproximativ 1600 de ingineri lucrează la acesta, fără a numi tehnicieni și administratori dedicați, unele facturi de energie electrică care sunt stratosferic (rețineți că astăzi centrele de date consumă 2% din energia electrică generată în întreaga lume, adică miliarde de wați și miliarde de euro. De fapt, doar Google consumă 0,01% din energia lumii, deci își instalează de obicei centrele de date în zone ale lumii în care energia electrică este mai ieftină, deoarece economisește multe milioane) etc. Vă puteți imagina că nu este ieftin să mențineți o echipă de acest gen ... și nu este pentru mai puțin, deoarece serverul monstruos pe care Facebook îl are în Oregon se află într-un depozit de aproximativ 28.000 m2 în valoare de sute de milioane de euro, un imens fermă de servere cu mii de procesoare, unități de hard disk pentru a adăuga mai multe PB de stocare, multe bănci de memorie RAM, plăci de rețea în sălbăticie (calculează că există 6 km de cabluri cu fibră optică pentru a le întrepăta) și toate consumă 30 MW de generatoare de electricitate și motorină ca mod UPS pentru întreruperi, generând toată căldura care necesită un sistem complex de disipare cu aer condiționat la scară largă.
Și asta este pentru cele mai importante caracteristici, deși pot exista aplicații specifice care au nevoie de lucruri mai specifice.
Tendințe actuale:
De la los sisteme aproape personalizate La fel ca primul de la IBM, CDC sau Cray, totul s-a schimbat foarte rapid odată cu sosirea cipurilor sau circuitelor integrate și a costului redus al acestora, permițând începerea noii supercomputere masiv paralele, cu mii de elemente. Cu toate acestea, nu credeți că supercomputerele actuale sunt sisteme simple care trebuie doar să reunească mii de dispozitive și atât, sunt mașini complexe care au nevoie de un design atent și o fabricație care să răsfețe fiecare detaliu pentru a profita la maximum de el totul funcționează fără adecvată în funcție de capacitățile sau caracteristicile pe care dorim să le realizăm.
După acele prime mașini compuse din circuite personalizate sau cipuri personalizate concepute aproape special pentru mașină, am început să folosim sisteme mult mai standard, cum ar fi microprocesoarele, așa cum vom vedea în secțiunea următoare.
Microprocesoare specifice:
La început, s-au folosit aproape aceleași cipuri de procesare utilizate în computerele de acasă, dar astăzi, companiile mari, precum IBM, AMD și Intel, proiectează modele specifice ale microprocesoarelor lor pentru desktop sau în alte scopuri. De exemplu, știm cu toții microprocesoarele IBM PowerPC, care au fost instalate în Apple până acum câțiva ani când au adoptat cipurile Intel. Aceleași cipuri care au fost utilizate în Apple au alimentat și supercomputerele. Cu toate acestea, IBM are mai multe modele specifice pentru mașini mari care obțin performanțe mai bune lucrând împreună, cum ar fi puterea, chiar dacă partajează ISA cu PowerPC-urile.
Același lucru se întâmplă și cu SPARC, care, deși nu au în prezent modele specifice pentru desktop, deoarece este un sector pe care nu îl domină sau pe care îl interesează foarte mult, da că în trecut existau stații de lucru cu aceiași microprocesoare, deși cele actuale sunt special concepute pentru lucrul pe aceste mașini grozave. Același lucru s-ar putea spune și pentru jetoane Intel și AMD, decât microprocesoarele specifice, cum ar fi Intel Xeon, care împărtășesc microarhitectura cu Core i3 / i5 / i7 / i9 actual și multe dintre caracteristicile sale (nu cu Intel Itanium), doar că sunt optimizate pentru a funcționa în modul MP. Același lucru este valabil și pentru AMD, care a proiectat o implementare specială pentru supercomputerele lor K8 sau Athlon64 numite Opteron, și în prezent EPYC (bazat pe Zen).
Aici mă opresc din nou și aș vrea să definesc tipurile de microprocesoare conform anumitor parametri:
Conform arhitecturii sale : în funcție de arhitectura procesorului sau a microprocesorului în sine, putem găsi: Microprocesor : Este un procesor sau microprocesor normal, indiferent de microarhitectura sau tehnologiile pe care le implementează. Microcontroler : este un procesor normal (de obicei cu performanțe scăzute) impulsionat pe același cip împreună cu o memorie RAM, un sistem I / O și o magistrală, adică un microcomputer pe un cip. În general, acestea nu sunt utilizate în supercomputere, dar sunt foarte prezente într-o multitudine de dispozitive domestice și industriale, plăci precum Arduino etc. Dar pentru problema supercomputerelor uitați-le ... DSP (procesor de semnal digital) : Puteți crede, de asemenea, că aceste procesoare digitale de semnal nu se potrivesc subiectului supercomputării, dar veți vedea cum au sens atunci când vedem mai multe despre calculul eterogen. Dar acum trebuie doar să știți că sunt procesoare specifice pentru a putea avea o performanță bună atunci când vine vorba de procesarea semnalelor digitale, ceea ce îl face bun pentru plăci de sunet, video etc. Dar acest lucru ar putea avea unele avantaje în anumite calcule, așa cum vom vedea ... SoC (System-on-a-Chip) : Este un sistem pe un cip, așa cum sugerează și numele său, adică un cip în care a fost inclus ceva mai mult decât ceea ce este inclus în microcontroler. În plus față de un procesor (de obicei ARM), acesta include și un bliț, RAM, I / O și unele controlere. Dar, în cazul SoC-urilor, CPU-ul integrat este de obicei performant și este destinat smartphone-urilor, tabletelor etc., deși acum există microservere care folosesc acest tip de cip ca unități de procesare așa cum vom vedea. Procesor vectorial : este un tip de microprocesor SIMD, adică execută o instrucțiune cu mai multe date. Se poate spune că multe microprocesoare moderne au funcții SIMD datorită acelor extensii multimedia precum MMX, SSE etc. despre care am vorbit. Dar când spun procesor vector mă refer la cele pure, care au fost proiectate pe baza procesării unui vector sau a unei matrice de date pentru fiecare instrucțiune. Exemple de acest tip de procesor sunt Fujitsu FR-V, utilizat în unele supercalculatoare japoneze, iar GPU-urile ar putea fi considerate ca atare. ASICs : Acestea sunt circuite integrate specifice aplicației, adică cipuri personalizate pe baza utilizării lor. Ceva care poate oferi performanțe excelente pentru anumite aplicații specifice, deși designul său implică un cost mai mare decât utilizarea unităților de procesare generice. De asemenea, dacă FPGA sunt utilizate pentru a le implementa, nu va fi cel mai eficient din punct de vedere electronic. De exemplu, acestea sunt utilizate pe scară largă astăzi pentru a construi mașini de extragere a criptomonedelor. alții : sunt alții care chiar acum pentru acest subiect nu suntem prea interesați, cum ar fi APU-uri (CPU + GPU), NPU-uri, microprocesor fără ceas, C-RAM, procesor baril etc.
: în funcție de arhitectura procesorului sau a microprocesorului în sine, putem găsi: După nucleele sau nucleele lor : am trecut de la procesoare mono-core sau single-core la a avea mai multe, dar în cadrul microprocesoarelor care au mai multe putem diferenția între: Multicore : acestea sunt multicorurile tradiționale pe care le folosim frecvent, cum ar fi dualcore, quadcore, octacore etc. Au de obicei 2, 4, 8, 12, 16, 32, ... nuclee sau nuclee, pe același cip sau în același ambalaj, dar cipuri diferite. Manycore : similare celor de mai sus, dar sunt de obicei sute sau mii de nuclee și, pentru a fi posibil, nucleele integrate trebuie să fie mai simple și mai mici decât proiectele Intel și AMD, de exemplu, precum și mai eficiente din punct de vedere energetic. De aceea, ele se bazează de obicei pe nuclee ARM, plasate sub formă de dale. Punând multe dintre acestea împreună, se pot atinge capacități de calcul foarte mari. Intel a cochetat, de asemenea, cu acest tip, cu Xeon Phi, care are multe nuclee x86 folosind nuclee mult mai simple, dar grupate în număr mare (57 până la 72) pentru a alimenta unele supercomputere actuale.
: am trecut de la procesoare mono-core sau single-core la a avea mai multe, dar în cadrul microprocesoarelor care au mai multe putem diferenția între: Conform utilizării sale: În acest caz, ne interesează doar un singur tip, care este MP sau sistemele multiprocesor. În computerul dvs. desktop sau laptop veți vedea că placa de bază are doar o singură priză unde să introduceți un microprocesor, pe de altă parte, plăcile de bază ale serverului au câte 2, 4, ... prize pe fiecare dintre ele, asta vreau să spun prin MP .
Dar microprocesoarele sunt deplasate treptat în favoarea altor unități de procesare mai specifice cu care se realizează capacități de calcul mai bune, adică o mai bună randament între FLOPS pe W realizat așa cum vom vedea în secțiunea următoare.
Alte metode de procesare:
După cum am spus, microprocesoarele se mișcă încetul cu încetul, deși au încă o cotă de piață mare, dar există și alte unități de procesare care intră puternic în ultima vreme, precum GPGPU sau GPU-uri cu scop general. Și este faptul că cipurile plăcilor grafice sunt de obicei de tip SIMD sau tip vector, care pot aplica aceeași instrucțiune la o multitudine de date simultan, cu creșterea performanței pe care aceasta o presupune.
Și, cel mai bine, modificând controlerul și programaticFără a modifica hardware-ul, aceste GPU-uri pot fi utilizate pentru prelucrarea datelor ca și cum ar fi un procesor, adică pentru procesare generală și nu numai pentru grafică așa cum o fac GPU-urile dedicate, permițând să profite de potențialul lor enorm de calcul, deoarece cantitatea de FLOPS-urile realizate de o placă grafică sunt mult mai mari decât cele ale unui procesor.
Motivul pentru care obțin o performanță de calcul atât de extraordinară este că sunt făcuți să lucreze cu grafice și acest lucru necesită o mulțime de calcul matematic pentru a le deplasa. Pe lângă faptul că sunt SIMD, așa cum am spus, ei urmează de obicei un tip de paradigmă de programare paralelă SIMT (Instrucțiune unică - fire multiple), obținând rate de transfer bune chiar și atunci când latența memoriei este mare.
Rețineți că pentru a genera un grafic 3D, este necesară o modelare care începe prin combinarea unei serii de triunghiuri cu coordonatele W, X, Y și Z pe plan, pentru a aplica apoi culoarea (R, G, B, A) și a crea suprafețele, a da iluminare, a textura suprafețele , mixt etc. Aceste date și coordonatele culorilor înseamnă că conțin procesoare configurabile pentru a le prelucra și se înțelege că aceste coordonate formează cu precizie vectorii cu care funcționează unitățile de procesare GPU și sunt cele care sunt utilizate pentru a face calcule de scop. De exemplu, în timp ce un procesor trebuie să execute 4 instrucțiuni de adăugare pentru a adăuga X1X2X3X4 + Y1Y2Y3Y4, adică X1 + Y1, apoi X2 + Y2 și așa mai departe, un GPU ar putea să o facă dintr-o dată.
Datorită acestui fapt, avem GPU-uri care funcționează la frecvențe de ceas foarte scăzute, de până la 5 sau 6 ori mai mici decât procesoarele și obțin o rată FLOPS mult mai mare, ceea ce înseamnă o raport FLOPS / W mai mare. De exemplu, un Intel Core i7 3960X atinge 141 GFLOPS de performanță de calcul, în timp ce un AMD Radeon R9 290X poate atinge 5.632 GFLOPS, care are un cost aproximativ al fiecărui GFLOP de aproximativ 0,08 €, în timp ce în 2004, un supercomputer japonez numit NEC Earth Simulatorul a fost lansat cu procesoare vectoriale și o performanță totală de 41.000 TFLOPS al căror cost pe GFLOPS a fost de aproximativ 10.000 €, deoarece era format din mii de procesoare cu câte 8 GFLOPS.
După cum puteți vedea, aici se află interesul pentru a crea supercomputerele curente bazate pe GPU de la NVIDIA sau AMD în loc să utilizeze procesoare. Și calculul eterogen devine, de asemenea, important, adică combinând diferite tipuri de unități de procesare și încredințând fiecare operație unității care o procesează în mai puțin timp sau mai eficient. Acest lucru se confruntă cu paradigma de calcul omogenă, în care CPU gestionează logica, GPU gestionează grafica, DSP-urile pentru semnale digitale etc.
În schimb, de ce să nu le folosiți pe toate așa cum este propus calcul eterogen pentru a optimiza performanța. Fiecare dintre aceste jetoane se pricepe la ceva, au avantajele și dezavantajele lor, așa că lăsați-le pe fiecare să facă ceea ce fac cel mai bine ...
Paralelism:
Și, deși nu aș vrea să fiu profitabil, cel puțin nu atât unități de supercomputerDa, aș vrea să mă întorc la sfârșitul paralelismului și să explic ceva mai mult. Și este, aproape de la începutul calculului, paralelismul s-a îmbunătățit într-un sens sau altul:
Paralelism la nivel de biți : Cu toții am văzut cum au evoluat microprocesoarele de la 4 biți, 8 biți, 16 biți, 32 biți și actualul 64 de biți (deși cu unele extensii multimedia care ajung la 128, 256, 512 etc.). Asta înseamnă că o singură instrucțiune poate opera mai multe date sau date mult mai lungi.
: Cu toții am văzut cum au evoluat microprocesoarele de la 4 biți, 8 biți, 16 biți, 32 biți și actualul 64 de biți (deși cu unele extensii multimedia care ajung la 128, 256, 512 etc.). Asta înseamnă că o singură instrucțiune poate opera mai multe date sau date mult mai lungi. Paralelism la nivel de date : când în loc de date scalare folosim vectori sau matrice de date pe care operează instrucțiunile. De exemplu, un scalar ar fi X + Y, în timp ce un DLP ar corespunde X3X3X1X0 + Y3Y2Y1Y0. Aceasta este exact ceea ce fac aceste extensii în seturile de instrucțiuni pe care le-am menționat în paralelism la nivel de biți.
: când în loc de date scalare folosim vectori sau matrice de date pe care operează instrucțiunile. De exemplu, un scalar ar fi X + Y, în timp ce un DLP ar corespunde X3X3X1X0 + Y3Y2Y1Y0. Aceasta este exact ceea ce fac aceste extensii în seturile de instrucțiuni pe care le-am menționat în paralelism la nivel de biți. Paralelism la nivel de instruire : tehnici care intenționează să proceseze mai multe instrucțiuni pe ciclu de ceas. Adică, obțineți un IPC <1. Și aici putem cita conducta, arhitecturile suprascalare și alte tehnologii ca metode principale pentru a-l atinge.
: tehnici care intenționează să proceseze mai multe instrucțiuni pe ciclu de ceas. Adică, obțineți un IPC <1. Și aici putem cita conducta, arhitecturile suprascalare și alte tehnologii ca metode principale pentru a-l atinge. Paralelism la nivel de sarcină : Mă refer la multithreading sau multithreading, adică obținerea mai multor fire sau sarcini propuse de programatorul de kernel al sistemului de operare pentru a fi efectuate simultan. Prin urmare, software-ul în acest caz va permite ca fiecare proces să fie împărțit în sarcini mai simple care pot fi realizate în paralel. Dacă în Linux utilizați comanda ps cu opțiunea -L, va apărea o coloană cu ID-ul LWP (Lightweight Proccess), adică un proces ușor sau un fir. Deși modalitățile de a ajunge la acest paralelism sunt mai multe: CMP (MultiProcessor Chip): adică, utilizați mai multe nuclee și fiecare procesează un fir. Multithreading : că fiecare procesor sau nucleu poate procesa mai mult de un fir în același timp. Și în cadrul multithreading, putem distinge, de asemenea, între mai multe metodologii: Multithread temporar sau superthreading: aceasta este ceea ce utilizează unele microprocesoare, cum ar fi UltraSPARC T2, ceea ce se face este că alternează între procesarea unuia și a celuilalt fir, dar ele nu sunt de fapt ambele procesând în paralel în același timp. Multithreading simultan sau SMT (MultiThreading simultan): în acest caz sunt procesate în paralel, permițând resurselor CPU să planifice dinamic și să aibă posibilitatea de a difuza mai multe transmisii. Aceasta este ceea ce folosește AMD sau Intel, deși Intel a înregistrat o marcă comercială care este HyperThreading, nu este altceva decât un SMT. Cu toate acestea, înainte de a adopta SMT în AMD Zen, AMD a folosit CMT (Clustered MultiThreading) în Fusion, adică un multithreading bazat pe nuclee fizice și nu pe nuclee logice. Cu alte cuvinte, în SMT fiecare nucleu sau procesor acționează ca și cum ar fi mai multe nuclee logice pentru a îndeplini aceste sarcini în paralel, pe de altă parte, în CMT sunt utilizate mai multe nuclee fizice pentru a efectua acest multithreading ...
: Mă refer la multithreading sau multithreading, adică obținerea mai multor fire sau sarcini propuse de programatorul de kernel al sistemului de operare pentru a fi efectuate simultan. Prin urmare, software-ul în acest caz va permite ca fiecare proces să fie împărțit în sarcini mai simple care pot fi realizate în paralel. Dacă în Linux utilizați comanda ps cu opțiunea -L, va apărea o coloană cu ID-ul LWP (Lightweight Proccess), adică un proces ușor sau un fir. Deși modalitățile de a ajunge la acest paralelism sunt mai multe: Paralelism la nivel de memorie: nu se referă la cantitatea de memorie instalată în sistem, prin urmare este un termen confuz. Se referă la numărul de accesuri în așteptare care pot fi făcute simultan. Majoritatea superscalelor au acest tip de paralelism, realizat grație implementării mai multor unități de preluare care satisfac diverse cereri de defecțiuni cache, TLB-uri etc.
Indiferent de aceste niveluri de paralelism, ele pot fi combinate cu altele tipuri de arhitecturi pentru a obține mai mult paralelism, cum ar fi:
Superscalar și VLIW : Pur și simplu, sunt acele unități de procesare (procesoare sau GPU-uri) care au mai multe unități funcționale replicate, cum ar fi mai multe FPU-uri, mai multe ALU-uri, mai multe unități de ramificare etc. Aceasta înseamnă că operațiunile efectuate de aceste tipuri de unități se pot face două câte două sau trei câte trei etc., în funcție de numărul de unități disponibile. De exemplu, dacă pentru a executa un proces sau program, trebuie să procesați instrucțiunile Y = X +1, Z = 3 + 2 și W = T + Q, într-un scalar ar trebui să așteptați finalizarea primei operații înainte de a introduce a doua una, în schimb dacă aveți 3 ALU, acestea se pot face simultan ... * VLIW: în cazul VLIW, ceea ce există de obicei este o replică a unor unități, iar compilatorul ajustează instrucțiunile pentru a le adapta la întreaga lățime a procesorului și că în fiecare ciclu sunt ocupate toate sau majoritatea unităților. Adică, VLIW este o instrucțiune lungă, care este alcătuită din câteva instrucțiuni mai simple, ambalate într-un mod specific, pentru a se conforma arhitecturii hardware. Cum veți înțelege acest lucru are avantajele și dezavantajele sale pe care nu le voi explica aici ...
: Pur și simplu, sunt acele unități de procesare (procesoare sau GPU-uri) care au mai multe unități funcționale replicate, cum ar fi mai multe FPU-uri, mai multe ALU-uri, mai multe unități de ramificare etc. Aceasta înseamnă că operațiunile efectuate de aceste tipuri de unități se pot face două câte două sau trei câte trei etc., în funcție de numărul de unități disponibile. De exemplu, dacă pentru a executa un proces sau program, trebuie să procesați instrucțiunile Y = X +1, Z = 3 + 2 și W = T + Q, într-un scalar ar trebui să așteptați finalizarea primei operații înainte de a introduce a doua una, în schimb dacă aveți 3 ALU, acestea se pot face simultan ... * VLIW: în cazul VLIW, ceea ce există de obicei este o replică a unor unități, iar compilatorul ajustează instrucțiunile pentru a le adapta la întreaga lățime a procesorului și că în fiecare ciclu sunt ocupate toate sau majoritatea unităților. Adică, VLIW este o instrucțiune lungă, care este alcătuită din câteva instrucțiuni mai simple, ambalate într-un mod specific, pentru a se conforma arhitecturii hardware. Cum veți înțelege acest lucru are avantajele și dezavantajele sale pe care nu le voi explica aici ... Conductă : canalizarea sau segmentarea se realizează prin introducerea de registre care împart circuitele, separând fiecare unitate funcțională în etape. De exemplu, imaginați-vă că aveți o conductă cu 3 adâncimi, în acest caz unitățile funcționale sunt împărțite în trei părți independente, ca și cum ar fi un proces de fabricație în lanț. Prin urmare, odată ce prima instrucțiune introdusă a renunțat la prima etapă, o alta ar putea intra deja în această primă etapă, accelerând executarea. Pe de altă parte, într-un sistem fără conducte, următoarea instrucțiune nu a putut fi introdusă până când prima nu a terminat complet.
: canalizarea sau segmentarea se realizează prin introducerea de registre care împart circuitele, separând fiecare unitate funcțională în etape. De exemplu, imaginați-vă că aveți o conductă cu 3 adâncimi, în acest caz unitățile funcționale sunt împărțite în trei părți independente, ca și cum ar fi un proces de fabricație în lanț. Prin urmare, odată ce prima instrucțiune introdusă a renunțat la prima etapă, o alta ar putea intra deja în această primă etapă, accelerând executarea. Pe de altă parte, într-un sistem fără conducte, următoarea instrucțiune nu a putut fi introdusă până când prima nu a terminat complet. Executarea din ordin: într-o arhitectură ordonată, instrucțiunile sunt executate secvențial pe măsură ce compilatorul le-a generat pentru a constitui programul care rulează. Pe de altă parte, aceasta nu este cea mai eficientă, deoarece unele pot dura mai mult sau trebuie să introducă bule sau momente moarte în CPU în așteptarea acelui eveniment care blochează rezultatul instrucțiunii. Pe de altă parte, în afara funcționării, acesta va alimenta în mod constant procesorul cu instrucțiuni, indiferent de ordine, crescând timpul productiv. Acest lucru se realizează prin algoritmi în care nu voi intra.
În general, majoritatea procesoarelor actuale, Intel, AMD, IBM POWER, SPARC, ARM etc. utilizează un amestec de toate nivelurile de paralelism, pipelined, superscalar, execuție în afara ordinii, redenumirea înregistrării etc., pentru a obține mult mai mult performanţă. Dacă doriți să aflați mai multe, puteți consulta Taxonomia lui Flynn, care diferențiază sistemele:
SISD : unitate de procesare care poate procesa doar o singură instrucțiune cu o singură dată. Adică execută secvențial instrucțiunile și datele, unul câte unul.
: unitate de procesare care poate procesa doar o singură instrucțiune cu o singură dată. Adică execută secvențial instrucțiunile și datele, unul câte unul. SIMD : o singură instrucțiune și mai multe date, în acest caz paralelismul este doar în calea de date și nu în calea de control. Unitățile de procesare actuale vor putea executa aceeași instrucțiune pe mai multe date în același timp. Acesta este cazul procesoarelor vectoriale, GPU-urilor și a unor extensii multimedia care au realizat acest lucru în cadrul microprocesoarelor (de exemplu: SSE, XOP, AVX, MMX, ...).
: o singură instrucțiune și mai multe date, în acest caz paralelismul este doar în calea de date și nu în calea de control. Unitățile de procesare actuale vor putea executa aceeași instrucțiune pe mai multe date în același timp. Acesta este cazul procesoarelor vectoriale, GPU-urilor și a unor extensii multimedia care au realizat acest lucru în cadrul microprocesoarelor (de exemplu: SSE, XOP, AVX, MMX, ...). MISD : în acest caz paralelismul este la nivelul instrucțiunilor, permițând executarea mai multor instrucțiuni pe un singur flux de date. Imaginați-vă că aveți X și Y și puteți opera simultan X + Y, XY, X · Y și X / Y.
: în acest caz paralelismul este la nivelul instrucțiunilor, permițând executarea mai multor instrucțiuni pe un singur flux de date. Imaginați-vă că aveți X și Y și puteți opera simultan X + Y, XY, X · Y și X / Y. MIMD: Este cea mai paralelă dintre toate, deoarece poate executa mai multe instrucțiuni pe mai multe date în același timp ...
Și cred că prin aceasta principiile paralelismului sunt destul de clare. Dacă doriți să mergeți mai adânc, puteți accesa sursele pe care le-am lăsat în zona finală a acestui articol și în care am lucrat în ultimii 17 ani din viața mea.
Sisteme de memorie:
Oricare ar fi metoda de procesare sau unitatea de procesare utilizată, este necesară o memorie. Dar aici intrăm în probleme ceva mai accidentate, deoarece, cu paralelismul, sistemele de memorie trebuie să fie coerente și au o serie de caracteristici pentru a nu genera date eronate. Nu vă faceți griji, vă voi explica într-un mod foarte simplu cu un exemplu.
Imaginează-ți că ai CPU unic Efectuând o instrucțiune de adăugare, imaginați-vă că acesta este Z = Y + X, în acest caz nu ar exista nicio problemă, deoarece CPU ar aduce instrucțiunea de adăugare și ar spune unității sale aritmetice să adauge locația de memorie Y și X unde sunt acelea date și, în final, va salva rezultatul în poziția Z a memoriei. Nici o problemă! Dar dacă există mai multe procesoare? Imaginați-vă același exemplu al acelui procesor A care face Z = Y + X, dar împreună cu un alt procesor B care face X = Y - 2.
bine, să-i dăm valori la fiecare dintre literele: Y = 5, X = 7. Dacă acesta este cazul, dacă CPU A acționează mai întâi, am avea Z = 5 + 7, adică Z = 12. Dar dacă CPU B acționează mai întâi, X = 5 - 2 = 3, prin urmare, ar accesa memoria și stocați 3 în adresa unde este stocat X, deci dacă CPU A accesează acea poziție, atunci ar face aceeași instrucțiune, dar rezultatul ar fi Z = 3 + 7, deci Z = 10. Ooops! Avem deja un eșec grav pe care nu ni-l putem permite, sau nimic nu ar funcționa corect ...
Din acest motiv, sistemele de memorie au dezvoltat o serie de metode pentru a menține această consistență și știți care operație ar trebui să meargă înainte sau după, astfel încât rezultatul să fie corect. Chiar și pe computerul dvs. de acasă se întâmplă acest lucru, deoarece acum aveți mai multe nuclee care accesează aceeași memorie și nu numai asta, sunt utilizate și microarhitecturi care profită de multithreading, sisteme suprascalare și execuție în afara ordinii, ceea ce compromite o astfel de consistență dacă nu se iau măsuri corective. Ei bine, imaginați-vă pe un supercomputer cu mii de astea ...
Dar desigur, costuri reduse de fabricație jetoane în masă și maturizarea tehnologiei Rețelele au condus la o schimbare rapidă către mașini cu multe procesoare interconectate și acest lucru a forțat, de asemenea, sistemul de memorie să se schimbe (vezi cuplarea), deoarece acele probleme care există într-un computer de acasă s-ar multiplica cu mii, având atât de multe procesoare care acționează simultan.
ese cuplare pe care le-am menționat a evoluat de-a lungul timpului, începând cu sisteme strâns cuplate cu o memorie principală partajată de toate unitățile de procesare; și cuplul slab, cu sisteme în care fiecare procesor are propria sa memorie independentă (distribuită). Pe de altă parte, în ultima perioadă cele două sisteme pe care le-am menționat s-au diluat treptat și s-au făcut progrese hibridizare, cu schemele UMA (Uniform Memory Access) și NUMA (Non-Uniform Memory Access), deși acesta este un alt subiect despre care aș putea vorbi pe larg și ne-ar da pentru un alt mega post.
Dacă doriți niște informații, spuneți-vă pe scurt că într-un Arhitectura UMA timpul de acces la memorie la oricare dintre pozițiile de memorie principale uniforme este același, indiferent de procesorul care efectuează accesul (înțeleg accesul ca o operație de citire sau scriere). Asta pentru că este centralizat.
În timp ce în NUMA, nu este uniform și timpul de acces va depinde de procesorul care îl solicită. Adică, există o memorie locală și o memorie nelocală, cu alte cuvinte, o memorie partajată și distribuită fizic. După cum veți înțelege, pentru ca acest lucru să fie eficient, latența medie trebuie redusă la maxim și ori de câte ori este posibil să stocați datele și instrucțiunile pe care un procesor le va executa local.
Viitor: calculul cuantic
La a fost post-siliciu și toate tehnologiile de înlocuire ale microelectronicii actuale sunt încă destul de imature și în stadii de dezvoltare. Presupun că nu va exista o tranziție radicală, dar că posibilitățile siliciului actual vor începe să fie epuizate până când acesta va atinge plafonul său fizic, și apoi va veni o eră a tehnologiilor hibride a căror bază va continua să fie siliciu pentru, în un viitor ceva mai îndepărtat pentru a da saltul către calculul cuantic ...
În acea tranziție cred ARM-urile vor juca un rol crucial și numeroasele nuclee pentru eficiența lor energetică (performanță / consum) și, aceasta este deja o opinie foarte personală, poate că în anii 2020 se va ajunge la limita de siliciu și în anii 2030 va continua să fie fabricată pe tehnologii de siliciu, profitând de investiții dintre turnătorii și făcându-le puțin mai largi, spuneți, deoarece o matriță mai mare înseamnă acum un cost de fabricație mai mare, dar atunci când nu trebuie să faceți acele investiții uriașe pentru a actualiza o turnătorie, presupun că stabilitatea va juca în favoarea prețului. Cu toate acestea, din partea proiectantului, va implica un efort de dezvoltare mai mare, deoarece pentru această creștere a suprafeței fără a reduce dimensiunea de fabricație pentru a presupune o creștere utilă a performanței, ar putea fi necesar să răsfețe mult microarhitecturile viitoare și să meargă mai mult spre microarhitecturi eficient ca acele brațe pe care le-am numit ...
Revenind la subiectul calculului cuantic, unele au fost deja construite calculatoare cuantice, dar sincer, văzând ceea ce am văzut, acestea sunt încă destul de limitate și au nevoie de mult mai multă dezvoltare pentru a deveni ceva practic pentru corporații și mult mai multe de parcurs înainte de a se maturiza suficient pentru a deveni ceva accesibil pentru case. După cum puteți vedea în imaginile care deschid această secțiune, acestea par încă obiecte de science-fiction destul de complexe care necesită răcire pentru a le menține aproape de zero absolut K (-273 ° C).
Această temperatură limitează aplicarea sa practică și masivă, așa cum este cazul supraconductori. În domeniul supraconductoarelor, s-au făcut pași importanți, dar temperatura de funcționare este încă mult sub 0 ° C, deși ar fi foarte interesant dacă ar putea să-i facă să funcționeze la temperatura camerei sau în margini ceva mai normale. În plus față de bariera de temperatură, trebuie abordați și alți factori problematici, cum ar fi faptul că bazele și fundamentele computerului binar actual nu funcționează pentru calculul cuantic ...
Am vrut să menționez supraconductorii, deoarece este una dintre tehnologiile pe care se bazează unele computere cuantice pentru a putea cuantifica sau izola acele qubite despre care vom vorbi. Cu toate acestea, nu este singura tehnologie bazală, o avem și noi calculatoare cuantice bazate pe ioni (atomi cu unul sau mai mulți electroni mai puțini) pe baza numărului de electroni ai qubitilor prinși în capcanele laser. O altă alternativă este calcul cuantic bazat pe rotiri nucleare, folosind stările de rotire ale moleculelor drept quibits ...
Lăsând capcanele deoparte, voi încerca să explic într-un mod foarte simplu ce este calculul cuantic, pentru ca toți să înțeleagă. Pe scurt, este un pas suplimentar în paralelism, permițând viitoarelor computere cuantice să proceseze o astfel de cantitate de date sau informații, permițându-ne în același timp să facem noi descoperiri și să rezolvăm probleme care acum nu pot fi rezolvate cu supercalculatoare. Prin urmare, acestea nu vor reprezenta doar o revoluție tehnologică, ci vor fi un mare impuls pentru știință și tehnologie în alte domenii și bunăstarea umanității.
Mergem cu explicația ușoară a ceea ce este un computer cuantic. Știți că computerele actuale se bazează pe sistemul binar, adică procesează biți care pot lua valoarea zero sau una (pornit sau oprit, tensiuni mari sau mici dacă o vedem din punctul de vedere al circuitelor) și aceste coduri binare sunt informații care pot fi procesate pentru a rula programe și a face tot ce putem face pe computerele noastre de astăzi.
În schimb, într-un computer cuantic biții cuantici (numiți qubiti, a biților cuantici) nu numai că funcționează în stările on sau off (1 sau 0), dar pot funcționa și în ambele stări, adică într-o suprapunere de stat (pornit și oprit). Acest lucru se întâmplă deoarece nu se bazează pe mecanica tradițională, ci pe legile fizicii cuantice. De aceea am spus că logica digitală sau binară este inutilă și că trebuie să dezvoltăm o altă logică cuantică pentru a baza noua lume a computerelor care ne așteaptă.
Exersați cu platforma IBM Q: un laborator online pe care IBM l-a creat astfel încât oricine să poată folosi computerul cuantic cu 16 qubit. Este un editor cu o interfață grafică bazată pe web pe care o puteți folosi pentru a vă crea programele ...
Prin urmare, această nouă unitate de qubituri de informații, care va înlocui bitul, are un potențial latent datorită acestui paralelism sau dualitate care ne permite să gestionăm multe mai multe posibilități sau date simultan. Te-am pus un exemplu Pentru a-l înțelege mai bine, imaginați-vă că aveți un program care adaugă doi biți (a, b) dacă un bit suplimentar este 0 și îi scade dacă acel bit suplimentar are valoarea 1. Deci, instrucțiunile încărcate în memorie ar fi ( adăugați a, b) în cazul în care bitul este 0 și (sub a, b) în cazul în care este 1. Pentru a obține ambele rezultate, adunare și scădere, trebuie să-l executăm de două ori, nu? Ce se întâmplă dacă starea acelui bit suplimentar ar putea fi în ambele stări în același timp? Nu mai trebuie să îl rulați de două ori, nu?
Un alt exemplu, imaginați-vă că aveți o instrucțiune NU aruncată peste 3 biți într-un computer non-cuantic. Dacă la momentul lansării respectivei instrucțiuni, acești trei biți au valoarea 010, rezultatul va fi 101. Pe de altă parte, aceeași instrucțiune cu qubituri, unde fiecare valoare poate fi în ambele stări în același timp, rezultatul ar da toate valorile posibile de o dată: 111, 110, 101, 100, 011, 010, 001 și 000. Aceasta pentru simulări științifice, criptografie, rezolvare matematică a problemeloretc, este uimitor.
Cine conduce calea în această tehnologie? Ei bine, în acest moment se pare că IBM este liderul, deși Google, Intel și alte companii sau universități concurează și lansează de fiecare dată prototipurile lor de computere cuantice capabile să gestioneze mai multe qubite, deși au o problemă adăugată celor deja menționate, și anume că uneori au nevoie de unele dintre aceste qubite ca qubituri de „paritate”, adică pentru a vă asigura că rezultatele nu sunt eronate.
Probleme: consum de energie electrică și căldură generată
El consumul și disiparea căldurii acestor mașini mari este o mare provocare pentru ingineri. Acesta încearcă să reducă drastic acest consum și să facă față căldurii într-un mod ieftin, deoarece sistemele de răcire implică și consum de energie electrică care trebuie adăugat la consumul propriu al computerului. De aceea sunt luate în considerare unele idei exotice, cum ar fi scufundarea centrelor de date sub mare, astfel încât să își folosească propria apă ca lichid de răcire (de exemplu: marca comercială Fluorinert de la 3M, care sunt lichide de răcire pe bază de fluor) și economisesc la sistemele complexe de aer condiționat sau de pompare a lichidului de răcire ...
După cum am spus, Google caută zonele cu cele mai ieftine tarife energetice să își instaleze centrele de server, deoarece, deși diferența este mică, de-a lungul anilor reprezintă multe milioane de economii în factura de energie electrică, presupun că în Spania au complicat-o cu tarifele pe care iubitul nostru Endesa le are pentru noi ...
Cu privire la densitatea călduriiDe asemenea, generează o altă problemă de bază și este reducerea duratei de viață a componentelor serverului sau supercomputerului, care afectează durabilitatea și caracteristicile de viață utilă pe care le descriem în secțiunea privind caracteristicile pe care ar trebui să le aibă un supercomputer. Și căldura se datorează performanței electrice a componentelor circuitului, care risipesc cea mai mare parte a energiei consumate sub formă de căldură, la fel cum se întâmplă cu motoarele cu ardere internă, ale căror performanțe nu sunt prea mari și pot varia de la 25-30% pentru benzină sau 30% sau mai mult pentru dieseluri, cu 40-50% pentru unele turbo. Asta înseamnă, de exemplu, în cazul benzinei, că doar 25 sau 30% din benzina pe care o consumați este de fapt folosită pentru a transfera puterea pe roți, restul de 75-70% este irosit ca căldură datorită fricțiunii elementelor. Ca detaliu să spunem că motoarele electrice pot atinge o eficiență de 90% sau mai mult ...
Deși acel exemplu de motoare nu este foarte relevant, cu aceasta vreau să vă anunț că ori de câte ori vedeți căldură într-un dispozitiv înseamnă că energia este irosită sub formă de căldură.
Odată ce aceste două probleme au fost prezentate și au fost clare raportul căldură / energieVă pot oferi exemplul supercomputerului chinez Tianhe-1A care consumă 4,04 MW de energie electrică, dacă ar fi instalat într-o țară în care kWh se taxează la 0,12 € ca în cazul Spaniei, asta ar însemna un consum de 480 € / oră (4000 kW x 0,12 €), ținând cont de faptul că este conectat pe tot parcursul anului, consumul anual de plătit se ridică la 4.204.800 € (480x24x365). Patru milioane de euro este o sumă deloc de neglijat a facturii la electricitate, nu?
Și este și mai enervant să o plătim dacă știm că din cauza ineficienței circuitelor noastre de cei 4.204.800 € doar un procent ne-a fost cu adevărat util, iar celălalt procent bun a fost irosit sub formă de căldură. Și nu numai asta, ci a trebuit să investim bani pentru a atenua acea căldură care este inutilă, dar care ne afectează echipele. În plus, având în vedere mediul, acest consum disproporționat este, de asemenea, o mare problemă dacă energia este obținută din surse care generează un anumit tip de poluare (neregenerabilă).
Un alt caz exemplar ar fi supercomputerul chinez care ocupă acum primul loc în Top500, adică în 2018 are cea mai mare putere de calcul. Se numeste Sunway TaihuLight și este destinat studiilor petroliere și altor aspecte științifice, cercetării farmaceutice și proiectării industriale. Rulează RaiseOS (Linux), folosește un total de 40.960 microprocesoare SW26010 care sunt multiple (fiecare cip are 256 de nuclee, cu un total de 10.649.600 de nuclee), hard disk-uri pentru a completa 20 PB de stocare și 1,31 PB de memorie RAM dacă adăugăm toate modulele. Aceasta vă oferă o putere de calcul de 93 PFLOPS (vă voi explica mai târziu ce sunt FLOPS dacă nu știți). Prețul său este de aproximativ 241 de milioane de euro și consumul se ridică la 15 MW, motiv pentru care ocupă poziția 16 în clasamentul celor mai eficiente din punct de vedere energetic (6,051 GFLOPS / W). Acei 15 MW înseamnă că trebuie să multiplicați factura de energie electrică pentru Tianhe-1A cu 3,75 ...
Raportul puterii de calcul este chiar măsurat în raport cu cantitatea de wați necesară pentru a genera acea cantitate de calcul, despre care vorbesc unitatea FLOPS / W. Cu cât o mașină poate genera mai multe FLOPS pe watt, cu atât va fi mai eficientă și cu atât va fi mai mică factura de energie electrică și temperatura generată, deci și costul de răcire. Chiar și această relație ar putea fi un factor limitativ, deoarece infrastructura pentru refrigerarea instalată nu ar permite o posibilă extindere viitoare dacă nu poate fi refrigerată în mod adecvat cu instalațiile pe care le avem. Amintiți-vă că acest lucru este, de asemenea, atent la una dintre caracteristicile pe care trebuie să le aibă: scalaritatea.
Taxonomia supercomputerului:
Ei bine, există multe modalități de a clasificați supercomputerele, dar sunt interesat să explic cum să le clasific în funcție de anumiți factori. După cum am spus, mulți nu consideră serverele ca supercalculatoare și consider că este o mare greșeală, deoarece sunt supercalculatoare sau, mai degrabă, supercalculatoarele sunt un anumit tip de server în care caută să îmbunătățească capacitățile de calcul.
Deci aș spune că tipurile de supercalculatoare conform utilizării sale sunet:
server de : Este un tip foarte comun de supercomputer care poate varia de la câteva microprocesoare și câteva module RAM și hard diskuri configurate cu un anumit nivel RAID, până la mașini mari cu mii de microprocesoare, o mulțime de RAM disponibilă și o capacitate mare de stocare. Și sunt numite servere tocmai pentru că sunt destinate să ofere un anumit tip de serviciu: stocare, găzduire, VPS, poștă, web etc.
: Este un tip foarte comun de supercomputer care poate varia de la câteva microprocesoare și câteva module RAM și hard diskuri configurate cu un anumit nivel RAID, până la mașini mari cu mii de microprocesoare, o mulțime de RAM disponibilă și o capacitate mare de stocare. Și sunt numite servere tocmai pentru că sunt destinate să ofere un anumit tip de serviciu: stocare, găzduire, VPS, poștă, web etc. Supercomputer : diferența dintre o fermă server și un supercomputer la nivel vizual este zero, nu puteți distinge între cele două. Singurul lucru care le diferențiază este că supercomputerele sunt destinate să efectueze calcule matematice sau științifice complexe, simulări etc. Prin urmare, calitatea care interesează cel mai mult aici este cea a calculului. Cu toate acestea, nu confundați termenul de supercomputer pe care l-am dat acestui grup și nu credeți că serverele și mainframe-urile nu sunt supercomputere (insist din nou).
: diferența dintre o fermă server și un supercomputer la nivel vizual este zero, nu puteți distinge între cele două. Singurul lucru care le diferențiază este că supercomputerele sunt destinate să efectueze calcule matematice sau științifice complexe, simulări etc. Prin urmare, calitatea care interesează cel mai mult aici este cea a calculului. Cu toate acestea, nu confundați termenul de supercomputer pe care l-am dat acestui grup și nu credeți că serverele și mainframe-urile nu sunt supercomputere (insist din nou). mainframe: Sunt supercalculatoare speciale, deși, prin definiție, sunt mașini mari și scumpe, cu capacități foarte mari de a gestiona cantități mari de date, cum ar fi păstrarea controlului civil de un fel, tranzacții bancare etc. Pe de altă parte, există o diferență clară între un mainframe și un supercomputer, și anume că mainframe-ul trebuie să-și îmbunătățească capacitățile de I / O și să fie mai fiabil, deoarece trebuie să acceseze cantități mari de date, cum ar fi bazele de date externe. În general, mainframe-urile sunt mai utilizate de către ministerele guvernamentale sau de anumite bănci sau companii, în timp ce supercomputerele sunt mult mai râvnite de oamenii de știință și militari. IBM este compania de frunte în mainframe-uri, cum ar fi z / Architecture bazată pe bestii de calcul precum cipurile sale și cu distribuții precum SUSE Linux pe ele ...
În ceea ce privește tipurile conform infrastructurii:
clustering : Este o tehnică de a uni computerele conectate între ele printr-o rețea pentru a crea un supercomputer mare, mainframe sau server. Adică, este baza despre care am vorbit în secțiunile anterioare. Centralizat: toate nodurile sunt situate în același loc, cum ar fi mainframele și majoritatea serverelor sau supercomputerelor. Distribuite: toate nodurile nu sunt situate în aceeași locație, uneori pot fi separate de distanțe mari sau distribuite în funcție de geografie, ci interconectate și funcționând ca și cum ar fi doar unul. Avem un exemplu în rețeaua spaniolă de supercomputere, care este formată din 13 supercomputere distribuite în toată peninsula. Cele 13 sunt interconectate pentru a oferi calculelor de înaltă performanță comunității științifice. Câteva nume de supercalculatoare care îl compun sunt: MareNostrum (Barcelona), Picasso (Málaga), Finisterrae2 (Galicia), Magerit și Cibeles (Madrid) etc.
: Este o tehnică de a uni computerele conectate între ele printr-o rețea pentru a crea un supercomputer mare, mainframe sau server. Adică, este baza despre care am vorbit în secțiunile anterioare. Procesare in retea: este un alt mod de exploatare și utilizare a resurselor eterogene necentralizate, în general capacitățile de calcul, stocarea etc., a diverselor dispozitive distribuite de întreaga lume pot fi utilizate pentru anumite aplicații. De exemplu, putem lua parte la puterea de calcul a mii sau milioane de desktopuri sau laptopuri ale multor utilizatori, smartphone-uri etc. Toate formează o rețea interconectată prin Internet pentru a rezolva o problemă. De exemplu, SETI @ home este un proiect de calcul distribuit sau mesh care funcționează pe platforma BOINC (Berkeley Open Infrastructure for Network Computing) cu care puteți colabora instalând un software simplu pe computer, astfel încât acestea să ia parte din resursele dvs. și să adăugați ei în acea rețea excelentă pentru căutarea vieții extraterestre. Un alt exemplu care mi se pare, deși nu este legal, este un malware care deturnează o parte din resursele computerului dvs. pentru a extrage criptomonede, există ...
Deși există alte modalități de catalogare a acestora, Cred că acestea sunt cele mai interesante.
Pentru ce sunt supercomputerele?
Ei bine, acele capacități mari de stocare, memorie sau calcul pe care le au supercomputerele ne permit să facem multe lucruri pe care nu le-am putea face cu un PC normal, cum ar fi anumite simulări științifice, rezolvarea problemelor matematice, cercetare, găzduire, oferirea de servicii către mii sau milioane de clienți conectați etc. Pe scurt, acestea sunt cel mai bun mod pe care îl cunoaștem pentru a accelera progresul uman, deși unele dintre lucrurile care sunt cercetate sunt distructive (utilizate în scopuri militare) sau pentru furtul confidențialității noastre, cum ar fi anumite servere de rețele sociale și alte cazuri pe care le cunoașteți cu siguranță.
Servere, date mari, cloud ...
Supercalculatoarele care ofera servicii sunt cunoscute sub numele de servere, după cum știți. Aceste servicii pot fi cele mai diverse:
Serverele de fișiere : pot fi de la servicii de găzduire sau găzduire pentru pagini web, stocare, servere FTP, rețele eterogene, NFS etc.
: pot fi de la servicii de găzduire sau găzduire pentru pagini web, stocare, servere FTP, rețele eterogene, NFS etc. Serverele LDAP și DHCP : alte servere deosebite care stochează date precum cele anterioare, deși funcția lor este alta, cum ar fi autentificarea centralizată ca în cazul LDAP sau pentru a furniza adrese IP dinamice ca în cazul DHCP ...
: alte servere deosebite care stochează date precum cele anterioare, deși funcția lor este alta, cum ar fi autentificarea centralizată ca în cazul LDAP sau pentru a furniza adrese IP dinamice ca în cazul DHCP ... Servere web : pot fi incluse în grupul anterior, deoarece stochează și date, dar sunt servere pur axate pe stocarea paginilor web, astfel încât să poată fi accesate prin protocolul HTTP sau HTTPS dintr-o rețea. Astfel, clienții vor putea accesa această pagină din browserele lor.
: pot fi incluse în grupul anterior, deoarece stochează și date, dar sunt servere pur axate pe stocarea paginilor web, astfel încât să poată fi accesate prin protocolul HTTP sau HTTPS dintr-o rețea. Astfel, clienții vor putea accesa această pagină din browserele lor. Servere de mail : Puteți furniza servicii de e-mail, astfel încât clienții să poată trimite și primi e-mailuri.
: Puteți furniza servicii de e-mail, astfel încât clienții să poată trimite și primi e-mailuri. Servere NTP : oferă un serviciu de sincronizare a timpului, foarte important pentru Internet. Acestea sunt abrevierile Network Time Protocol și sunt distribuite în straturi, cele mai joase straturi fiind cele mai precise. Aceste straturi principale sunt guvernate de ceasuri atomice care au variații foarte reduse pe tot parcursul anului, astfel încât oferă un timp super-precis.
: oferă un serviciu de sincronizare a timpului, foarte important pentru Internet. Acestea sunt abrevierile Network Time Protocol și sunt distribuite în straturi, cele mai joase straturi fiind cele mai precise. Aceste straturi principale sunt guvernate de ceasuri atomice care au variații foarte reduse pe tot parcursul anului, astfel încât oferă un timp super-precis. alții: alte servere pot stoca baze de date mari, date mari, chiar și o multitudine de servicii cloud (IaaS, PaaS, CaaS, SaaS). Un exemplu este VPS (Virtual Private Server), adică, într-un server mare, sunt generate zeci sau sute de servere virtuale izolate în cadrul mașinilor virtuale, iar clienților li se oferă posibilitatea de a deține unul dintre aceste servere pentru sarcinile pe care le dorește fără a fi nevoiți să plătească. un server real și plătiți pentru infrastructură și întreținere, plătiți doar o taxă pentru achiziționarea acestui serviciu de la furnizor ...
Și cu aceasta terminăm cel mai remarcabil din această categorie.
IN ABSENTA:
Unele supercomputere sunt concepute pentru a implementați sisteme AI (Inteligență Artificială), adică structuri capabile să învețe prin utilizarea rețelelor neuronale artificiale, fie implementate de algoritmi software, fie de cipuri neuronale. Unul dintre exemplele pe care le am acum în minte este supercomputerul IBM Blue Gene și algoritmul BlueMatter dezvoltat de IBM și Universitatea Stanford pentru a putea implementa un creier uman artificial într-un supercomputer și, astfel, analiza ce se întâmplă în el în unele boli psihice sau boli neurodegenerative precum Alzheimer, înțelegând astfel mai bine ce se întâmplă în interiorul creierului și fiind capabil să avanseze în tratamente noi sau să aibă cunoștințe mai mari despre cel mai misterios organ al nostru.
De asemenea, multe servicii AI pe care le folosim se bazează pe un supercomputer, cum ar fi Siri sau Amazon (vezi Alexa pentru Echo) etc. Dar poate este exemplul care mă interesează cel mai mult IBM Watson, un supercomputer care implementează un sistem informatic AI numit și Watson, care este capabil să răspundă la întrebări formulate în limbaj natural și alte incidente pentru care a fost programat, cum ar fi „gătitul” sau cunoașterea anumitor amestecuri de ingrediente care pot fi plăcute pentru gust .
Se bazează pe o bază de date mare, cu o multitudine de informații din cărți, enciclopedii (inclusiv Wikipedia în limba engleză) și multe alte surse în care puteți căuta informații pentru a oferi răspunsuri. Se bazează pe microprocesoare IBM POWER7 și are aproximativ 16 TB RAM și câteva PB de stocare pentru a stoca acea cantitate mare de informații, hardware care a costat peste 3 milioane de dolari. În plus, dezvoltatorii săi spun că poate procesa 500 GB de informații pe secundă. Și spre bucuria noastră, se bazează pe unele proiecte gratuite și pe un sistem de operare SUSE Linux Enterprise Server.
Aplicații științifice:
Dar supercalculatoarele sunt folosite mai ales pentru aplicații științifice, fie pentru cercetare în general, fie pentru o anumită utilizare militară. De exemplu, ele sunt utilizate pentru a efectua o multitudine de calcule asupra fizicii cuantice și nucleare, studii asupra materiei, cum ar fi supercomputerul CERN, simulări pentru a înțelege modul în care se comportă moleculele sau particulele elementare, simulări de fluide, cum ar fi CFD utilizate pentru studierea erodinamicii de mașini de curse, avioane etc.
De asemenea, pentru alte studii de chimie, biologie și medicină. De exemplu, pentru a încerca să înțelegeți mai bine comportamentul anumitor boli sau pentru a recrea modul în care tumorile se reproduc și astfel încercați să găsiți o soluție mai bună pentru cancer. Dan Brown a spus despre MareNostrum că poate vindecă cancerul, sperăm că va fi și cu cât va fi mai devreme cu atât mai bine. La UMA (Universitatea din Malaga) lucrează Miguel Ujaldon că am putut să intervievăm la LxA exclusiv pentru evoluțiile sale cu NVIDIA CUDA în supercomputere și el poate vorbi despre aceste evoluții care ne vor îmbunătăți sănătatea ... De asemenea, mă pot gândi la alte aplicații practice, cum ar fi studiul și predicția naturii naturale fenomene cum ar fi vremea, studii ale catenelor și mutațiilor ADN-ului, plierea proteinelor și analiza exploziei nucleare.
Rețineți că pentru toate aceste studii și investigații sunt necesare cantități uriașe de calcule matematicieni foarte precise și mutarea multor date foarte repede, ceva care, dacă oamenii ar trebui să o facă cu singurul ajutor al intelectului lor, ar putea dura secole pentru a găsi soluția, în timp ce cu aceste mașini în câteva secunde a fost capabil să se dezvolte o cantitate brutală de procese matematice.
Care sunt cei mai puternici din lume?
Am sugerat deja în unele cazuri, există un lista celor mai puternice 500 de supercalculatoare din lume care sunt actualizate periodic. Este despre Top500, unde veți găsi, de asemenea, o multitudine de statistici despre aceste mașini, informații etc., precum și o altă listă specială numită Green500 care se concentrează pe acea eficiență energetică, adică nu numai pe măsurarea FLOPS-urilor brute pe care mașina le poate dezvolta, ci și pe lista celor 500 de mașini cu cel mai bun raport FLOPS / W.
Cu toate acestea, pot exista supercalculatoare mult mai puternice decât acestea care nu apar pe listă, fie pentru că sunt destinate proiecte guvernamentale secrete sau pentru că datorită caracteristicilor lor nu îndeplinesc anumite cerințe pentru a fi analizate prin testele de referință pe care le vom descrie în secțiunea următoare și, prin urmare, rezultatele nu au fost publicate în acest Top500. În plus, se suspectează că unele dintre mașinile bine poziționate de pe această listă pot modifica aceste rezultate, deoarece acestea sunt optimizate în mod specific pentru a obține un scor bun în aceste analize de performanță, deși în practică nu este atât de mult.
valori de referință
Testele pentru a poziționa aceste supercomputere pe lista Top500 sau pentru a măsura performanța tuturor celor care se află în afara listei respective sunt bine cunoscute de toți, de fapt sunt similare sau egale cu cele pe care le efectuăm pe computerele de acasă sau pe dispozitivele noastre mobile pentru a le vedea performanța ta. Vorbesc despre software valori de referință. Aceste tipuri de programe sunt bucăți de cod foarte specifice care efectuează anumite operații matematice sau bucle care servesc la măsurarea timpului necesar mașinii pentru a le efectua.
Segun nota obținută, va fi poziționat pe lista menționată sau performanța pe care această mașină o poate avea în lumea practică va fi determinată pentru acele investigații pe care le-am detaliat mai sus. De obicei, benchmark-urile testează și alte componente, nu doar unitatea de procesare, ci și memoria RAM, placa grafică, hard disk, I / O etc. În plus, acestea sunt cele mai practice nu numai pentru a cunoaște performanța la care poate ajunge o mașină, ci pentru a ști ce trebuie îmbunătățit sau extins ...
L tipuri de teste Ele pot fi clasificate în sintetice, nivel scăzut / înalt și altele. Primele sunt acele teste sau programe care sunt proiectate special pentru a măsura performanța (de exemplu: Dhrystone, Whetstone, ...), în timp ce cele de nivel scăzut sunt cele care măsoară performanța unei componente în mod direct, cum ar fi latența unei memorii , timpi de acces la memorie, IPC etc. În schimb, cele de nivel înalt încearcă să măsoare performanța seturilor de componente, de exemplu, viteza de codificare, compresie etc., ceea ce înseamnă măsurarea performanței generale a componentei hardware care interferează în ea, driverul și manipularea că sistemul de operare o face. Restul testelor pot fi utilizate pentru a măsura consumul de energie, temperatura, rețelele, zgomotul, sarcinile de lucru etc.
Poate că cel mai cunoscut program de benchmarking pe supercomputer este LINPACK, deoarece a fost conceput pentru a măsura performanța în sistemele științifice și inginerești. Programul folosește intens operațiunile în virgulă mobilă, prin urmare rezultatele depind foarte mult de potențialul FPU al sistemului și tocmai acest lucru este cel mai important de măsurat în majoritatea supercomputerelor. Și aici putem măsura acea unitate despre care am vorbit atât de mult în tot articolul: FLOPS.
L FLOPS (operații în virgulă mobilă pe secundă) Măsoară numărul de calcule sau operații în virgulă mobilă pe care computerul le poate efectua într-o secundă. Știți deja că computerele pot efectua două tipuri de operații, cu numere întregi și cu virgulă mobilă, adică cu numere din setul de numere naturale (... -3, -2, -1,0,1,2,3, ... ) și cu seturi de numere raționale (fracții). Tocmai atunci când lucrăm cu simulări, grafică 3D sau calcule matematice complexe, fizică sau inginerie, aceste operații în virgulă mobilă sunt cele mai abundente și suntem interesați de o mașină care le poate gestiona mai repede ...
Numele multiplu scurt Echivalenţă - FLOPS 1 Kilogram KFLOPS 1000 Mega MFLOPS 1.000.000 Giga GFLOPS 1.000.000.000 tera TFLOPS 1.000.000.000.000 peta PFLOPS 1.000.000.000.000.000 exa EFLOPURI 1.000.000.000.000.000.000 Zeta ZFLOPS 1.000.000.000.000.000.000.000 Yota YFLOPS 1.000.000.000.000.000.000.000.000
Adică vorbim despre mașină Sunway TaihuLight Poate efectua la sarcină maximă aproximativ 93.014.600.000.000.000 de operații în virgulă mobilă în fiecare secundă. Impresionant!
Părți ale unui supercomputer: cum sunt construite?
Ați văzut deja de-a lungul articolului multe fotografii ale acestora ferme de servere, acele camere mari tipice care au o multitudine de cabluri prin tavan sau sub podea care interconectează acele dulapuri mari care se aliniază ca pe coridoare. Ei bine, acum este timpul să vedem ce sunt aceste dulapuri și ce conțin în interior, deși, în acest moment, cred că știți deja destul de bine despre ce vorbim.
Părți ale unui supercomputer:
Dacă te uiți la imaginea anterioară a arhitecturii unui supercomputer IBM, se arată destul de bine cum sunt constituite. Poate fi apreciat bine părțile de la cel mai simplu la setul asamblat. După cum puteți vedea, componenta elementară este cipul, adică CPU sau microprocesorul care este utilizat ca bază. De exemplu, imaginați-vă că este un AMD EPYC. Apoi, a spus AMD EPYC va fi introdus într-o placă de bază care are de obicei două sau patru prize, prin urmare fiecare dintre ele va avea 1 sau 2 EPYC, spre deosebire de plăcile de bază pe care le avem în computerele noastre non-MP.
Ei bine, avem deja o placă cu mai multe jetoane și, bineînțeles, placa de bază va avea și componentele normale adăugate. baza plăcii pe un computer de acasă, adică bănci de memorie etc. Una dintre aceste plăci este adesea numită calculează mașina așa cum vedeți în imagine. Și sunt de obicei aranjate în sertare metalice singure sau grupate în mai multe. Aceste sertare sunt cele pe care le vedeți în fotografia demonică card nod. Aceste noduri sau sertare sunt inserate în șine care au de obicei măsurători standard pe grupe (planul mediu), deși nu întotdeauna toate corespund nodurilor cu mașini de calcul, dar anumite golfuri sunt lăsate libere în partea de jos și în partea de sus pentru a adăposti alte „sertare” sau noduri cu plăcile de rețea și sistemele de legătură care vor interconecta toate aceste elemente cu alte dulapuri, alimentatorul sau sursa de alimentare, alte tăvi care vor conține hard disk-urile configurate în RADI etc.
Acele șine în care sunt inserate aceste „sertare” sau noduri despre care am vorbit sunt montate în două moduri posibile: lama și rack (rafturi), ca cea pe care o vedem în diferitele fotografii. Așa cum am spus deja, ele au de obicei măsurători standard, astfel încât elementele care vor intra în interior să se potrivească bine, așa cum se întâmplă cu un computer de birou, cu măsurători în inci, astfel încât să nu existe nicio problemă la introducerea vreunei componente în golfuri. În plus, rakurile nu merg de obicei singure, deoarece pot fi grupate și în grupuri care arată ca dulapuri mari, cu alte elemente auxiliare, dacă este necesar.
În funcție de dimensiunea mainframe-ului, serverului sau supercomputerului, numărul de dulapuri va fi mai mare sau mai mic, dar acestea vor fi întotdeauna interconectate între ele prin intermediul cardurilor de rețea, de obicei folosind sisteme puternice sisteme de interconectare performanțe ridicate și fibră optică, astfel încât să funcționeze ca un singur computer. Amintiți-vă că vorbim despre cele distribuite, prin urmare, aceste dulapuri pot fi în aceeași clădire sau distribuite în alte locații, caz în care vor fi conectate la o rețea WAN sau Internet, astfel încât să funcționeze împreună. Apropo, rețelele care ar face de râs cele mai rapide conexiuni de fibră de acasă ...
Tipuri de răcire:
Am vorbit deja despre preocuparea pentru refrigerareDe fapt, un lucru care iese în evidență atunci când intri într-o fermă de servere sau într-un centru de date este zgomotul mare care există de obicei în unele și schițe. Acest lucru se datorează acestor sisteme de răcire care trebuie să mențină sistemele la o temperatură adecvată. Și ceea ce vedeți în imaginea de mai sus nu este nici mai mult și nici mai puțin decât o cameră în care se află întregul sistem de refrigerare auxiliar al unuia dintre acești centre, deoarece vedeți că este destul de mare, complex și nu pare „ieftin” de întreținut.
Cele răcite cu aer au nevoie de uriașe camere cu aer condiționat, Dacă vă plângeți de factură vara pentru că v-ați pus gadgetul, imaginați-vă acestea. Și asta generează acel zgomot și curenți mari pe care i-am spus mai înainte. Și în cazul ființei lichid răcit, lucrul nu este mult mai bun așa cum este apreciat, cu cadre sofisticate de țevi, inspecția consecventă pentru a evita scurgerile și necesitatea de a utiliza mii sau milioane de litri de apă.
Se discută despre utilizarea apei reciclate în stațiile de tratare sau captarea apei de ploaie pentru a nu risipa aceste cantități uriașe de apă și, de asemenea, despre ceea ce am menționat anterior, localizarea centrelor de date în mare sau pe platforme peste ocean pentru a folosi apa de mare ca agent frigorific. În prezent, apa este trecută prin sursele de căldură pentru a extrage aceste grade suplimentare și apoi apa fierbinte este pompată până la turelele de răcire, astfel încât să fie răcită din nou și ciclul să înceapă din nou. S-au propus și alte metode experimentale care utilizează alți agenți frigorifici lichizi în sistemele de schimb pentru a reduce temperatura apei, fără compresoare de fluid scumpe.
Rețele de interconectare:
Rețelele prin care interconectare diferitele noduri și rak-uri ale serverelor sau supercomputerelor sunt rețele ultra-rapide din fibră optică, deoarece ar trebui evitate blocajele care ar face această paradigmă a elementelor de grupare masiv paralele mai puțin eficiente. Dacă aparatul are o conexiune cu exteriorul, adică dacă este conectat la Internet, lățimea de bandă pe care o manipulează este extrem de mare, după cum vă puteți imagina.
De exemplu, tehnologiile de interconectare cluster Myrinet și Infiniand sunt tipice. De exemplu, în cazul Myrinet Este alcătuit din plăci de rețea dezvoltate special pentru acest tip de conexiune care vor fi plasate într-un sertar sau nod pe care îl descriem în secțiunea pieselor. Cablurile de fibră optică (amonte / aval) conectate la un singur conector le vor ieși / vor intra. Interconectările se fac prin comutatoare sau routere, care vor fi în dulapuri. De asemenea, tind să aibă o toleranță bună la defecțiuni și au evoluat pentru a atinge viteze de 10 Gbit /.
În schimb, Infiniband este mai avansat și este metoda utilizată cel mai mult. Este un sistem cu viteză mare, latență redusă și cheltuieli reduse ale procesorului, ceea ce reprezintă un avantaj față de Myrnet, permițând utilizarea puterii procesorului în scopurile pentru care este destinat să fie utilizată, scăzând minimul pentru gestionarea sistemului. . În plus, este un standard menținut și dezvoltat nu de o companie ca cea anterioară, ci de o asociație numită IBTA.
La fel ca Myrnet, Infiniband folosește carduri de rețea (conectate la sloturi PCI Express) pentru conexiuni, cu cabluri de fibră optică, cu un autobuz serial bidirecțional care evită problemele autobuzelor paralele asociate distanțelor mari. În ciuda faptului că este serial, poate atinge viteza de 2,5 Gbit / s în fiecare direcție a fiecărei legături, atingând un randament maxim în unele dintre versiunile sale de aproximativ 96 Gbps.
Întreținere și administrare:
Supercomputerele sau serverele vor avea un batalion de personal, toți sunt cu adevărat interesați de funcțiile sau serviciile pe care le are de fapt mașina. În mod normal, suntem obișnuiți în computerele de acasă cu faptul că tindem să fim administratorii sistemelor noastre și, de asemenea, utilizatorii care îl folosesc. Dar asta nu se întâmplă în aceste cazuri, în cazul în care, dacă este un server, utilizatorii vor fi clienții și dacă este un supercomputer, utilizatorii vor fi oamenii de știință sau cine îl folosește ...
Ingineri și dezvoltatori : pot avea grijă ca utilajul sau funcționarea să fie corectă.
: pot avea grijă ca utilajul sau funcționarea să fie corectă. Administratori de sistem: administratorii de sistem vor fi responsabili de gestionarea sistemului de operare instalat pe supercomputer, astfel încât acesta să funcționeze corect. În general, aceste servere sau supercomputere nu au de obicei medii desktop sau interfețe grafice, deci totul se face de obicei de la terminal. Acesta este motivul pentru care administratorii de sisteme se pot conecta fizic la mașină printr-un terminal prost sau, dacă este posibilă administrarea de la distanță, se vor conecta de la distanță prin ssh și alte protocoale similare pentru a executa comenzile necesare.
Alți administratori : dacă există baze de date, pagini web și alte sisteme prezente pe mașină.
: dacă există baze de date, pagini web și alte sisteme prezente pe mașină. Experți în securitate : pot fi de mai multe tipuri, unele care se ocupă de securitatea fizică sau perimetrală, adică cu camere de supraveghere, securitate în accesele la centrul de date, de asemenea, care evită posibile accidente (de exemplu: incendii) etc., dar de asemenea, experți în securitate care securizează sistemul pentru a evita posibilele atacuri.
: pot fi de mai multe tipuri, unele care se ocupă de securitatea fizică sau perimetrală, adică cu camere de supraveghere, securitate în accesele la centrul de date, de asemenea, care evită posibile accidente (de exemplu: incendii) etc., dar de asemenea, experți în securitate care securizează sistemul pentru a evita posibilele atacuri. tehnicieni: că vor exista și cele mai variate, cu tehnicieni care se ocupă de întreținerea infrastructurii, tehnicieni de rețea, tehnicieni care se ocupă de înlocuirea componentelor deteriorate sau repararea acestora etc. În mod normal, au terminale stupide și în ele un software le spune sau marchează componenta deteriorată și, ca și cum ar fi un joc cu grilă, ar da o serie de coordonate, astfel încât tehnicianul să știe la ce culoar și rack să meargă pentru a înlocui element specific care eșuează. Prin urmare, coridoarele și rafturile vor fi marcate ca și cum ar fi o parcare. În plus, în interiorul camerei există de obicei rafturi cu cutii cu elemente de rezervă pentru a le putea înlocui pe cele care nu reușesc. Desigur, acest lucru se face la cald, adică fără a opri sistemul. Ei extrag nodul, înlocuiesc componenta, introduc nodul și se conectează în timp ce restul continuă să funcționeze ...
Când am spus termenul terminal mutMă refer la un tip de masă cu roți care se găsesc de obicei în aceste tipuri de centre și care au ecran și tastatură. Această centrală poate fi conectată la server sau supercomputer, astfel încât tehnicianul sau administratorul de sistem să poată efectua verificările.
Sisteme de operare:
După cum știți deja, Linux a fost creat cu scopul de a cuceri sectorul desktop, dar paradoxal este singurul sector pe care nu îl domină astăzi. desktopul este aproape monopolizat de Microsoft și Windows, urmat cu mult în urmă de Apple MacOS cu o cotă de aproximativ 6-10% și 2-4% pentru GNU / Linux ...
Cifrele nu sunt foarte fiabile, deoarece sursele dedicate realizării acestor studii nu fac uneori testele într-un mod adecvat sau sunt părtinitoare în anumite zone ale planetei ... În plus, unele includ ChromeOS și altele doar distros GNU / Linux la acea cotă. De exemplu, NetMarketShare a publicat un studiu care a plasat Linux la 4,83% și MacOS la 6,29%, adică destul de aproape. Presupun că în acest studiu au inclus și ChromeOS. Cu toate acestea, este puțin comparativ cu 88,88% pe care îl oferă Windows, deși mult mai bun decât FreeBSD (0,01%) și alte sisteme de operare care nici măcar nu sunt egale cu FreeBSD.
Pe de altă parte, aceste cifre timide nu apar în sectoare precum marile mașini, încorporat, dispozitive mobile etc. De exemplu, în sectorul supercomputerului, care este cel care ne preocupă acum, dominația este aproape insultătoare și absolută. Dacă te uiți la lista celor mai puternice supercomputere din lume, statisticile din iunie 2018 spun că 100% din cele mai puternice 500 folosesc Linux.
Dacă ne întoarcem în 1998, nu exista decât un supercomputer Linux printre acestea 500 mai puternic. În 1999, cifra a crescut la 17, încă una în anul următor, 28 în 2000, și de acolo au crescut exponențial, ajungând la 198 în 2003, 376 în 2006, 2007 a ajuns la 427 și de acolo au crescut puțin treptat până la atingerea cifrelor de aproximativ 490 din 500 care au oscilat până la atingerea actualului 500 din 500.
Prin urmare, în aceste servere, mainfram-uri sau supercalculatoare cu securitate totală veți vedea distrosurile Red Hat și SUSE, RHEL sau SLES instalate pe ele sau alte distribuții diferite cum ar fi Debian, CentOS, Kylin Linux etc. În cazul în care nu aveți Linux, acesta ar avea alte UNIX, cum ar fi Solaris, AIX, UX sau BSD, dar cele care sunt evidente prin absența lor sunt MacOS și Windows. Și așa cum am comentat în secțiunea anterioară, în general fără un mediu desktop, deoarece doriți să alocați toată puterea acestor computere scopului pentru care au fost proiectate și să nu risipiți o parte din acesta în medii grafice care, în plus, sunt de puțin interes pentru cei care se ocupă de ele. Un alt lucru diferit sunt computerele client de unde lucrează utilizatorii sau oamenii de știință, care vor avea medii grafice pentru o analiză a informațiilor într-un mod mai intuitiv și grafic.
Cum se creează un supercomputer de casă?
Puteți crea un supercomputer de casă, da. De fapt, în rețea veți găsi câteva proiecte, cum ar fi supercomputerele formate din mai multe plăci Raspberry Pi s-a alăturat. Evident, capacitățile acestor mașini nu vor proveni din altă lume, dar permit adăugați capacitățile multora dintre aceste plăci și să-i facă să funcționeze ca și cum ar fi o singură mașină. Mai mult decât pentru uz practic, acest tip de proiect DIY este făcut pentru a învăța cum puteți face un supercomputer, dar într-un mod mai ieftin și la o scară mai mică, astfel încât oricine să o poată face acasă.
Se numește un alt tip de cluster sau supercomputer care poate fi fabricat acasă sau mai ieftin decât mașinile mari Beowulf. Poate fi implementat cu orice tip de Unix, cum ar fi BSD, Linux sau Solaris și folosind proiecte open source pentru a profita de această uniune paralelă de mașini. Practic, realizează conectarea mai multor PC-uri conectate prin carduri Ethernet și comutatoare pentru a le uni și a le face să funcționeze ca un singur sistem.
Cu mai multe PC-uri vechi sau pe care nu îl utilizați și orice distribuție Linux, cum ar fi Ubuntu, ați putea să vă construiți Beowulf. Vă sfătuiesc să examinați proiectele MOSIX / OpenMOSIX o PelicanHPC. Cu ei veți putea realiza această implementare. Cu toate acestea, dacă vă atrage atenția, voi încerca în viitor să fac un tutorial în LxA despre cum să-l implementați într-un mod practic și pas cu pas.
Instalați un sistem de operare pe computer
Această secțiune este destul de ușor de descris, deoarece instalarea este practic la fel ca în orice computer. Doar că trebuie să avem în vedere faptul că ar trebui să configurăm anumite aspecte, cum ar fi configurația LVM sau RAID care este utilizată. Dar, în general, nu este prea departe de o instalare de zi cu zi. Singurul lucru șocant este că, în loc de un singur procesor și unele module RAM și unul sau două hard disk-uri, există sute sau mii, deși din punctul de vedere al administratorului nu există nicio diferență. Sistemul va vedea mașina ca un întreg, doar că resursele pe care le avem sunt extraordinare.
Ceea ce veți observa, de asemenea, diferența va fi absența BIOS / UEFIdeoarece aceste sisteme folosesc adesea diferite sisteme EFI sau alte implementări de firmware foarte specifice pentru anumite platforme bazate pe SPARC, POWER etc. De exemplu, Intel EFI este acceptat pentru Intel Itanium, De fapt, dacă ne citiți regulat, veți cunoaște și proiectul magnific al Linuxboot. Dar acest lucru nu prezintă prea multe probleme, doar familiarizați-vă cu această interfață și nimic altceva, în plus, de câte ori acest tip de echipament este oprit / pornit sau repornit este practic nul.
Mama tata! Pot avea un supercomputer acasă?
Indiferent de prototipurile pe care le putem asambla folosind formatul Beowulf sau grupul de plăci Raspberry Pi sau alte tipuri de SBC-uri, am vești bune pentru dvs. Puteți utiliza puterea unui supercomputer de acasă, fără a cumpăra sau monta nicio infrastructură. Doar plătind o taxă lunară pentru cumpărați acest serviciu vă puteți baza pe toată acea putere disponibilă pentru orice scop doriți să o utilizați. Și asta datorită diferitelor servicii cloud, cum ar fi AWS (Amazon Web Services), Google Cloud Computing, Microsoft Azure, IBM etc.
În plus, angajarea acestui tip de serviciu nu înseamnă doar economii în comparație cu propriul server dedicat, ci permite și alte avantaje. De exemplu, ne permite să creștem rapid potențialul sau dimensiunea serviciului nostru prin angajarea unei rate ușor mai mari, lucru care, dacă l-am avea fizic, ar însemna cumpărarea de echipamente noi. Nici nu trebuie să plătim cheltuieli suplimentare, cum ar fi consumul de energie electrică sau personalul de întreținere, deoarece acestea vor fi asigurate de tehnicienii furnizorului, ceea ce ne va permite să vă oferim garanții de fiabilitate la un preț bun.
Există multe servicii care ofera VPS-uri la un pret bun, adică un server virtual implementat pe o mașină virtuală într-un server real sau supercomputer. Acest server va accesa o parte din capacitățile mașinii reale pe care vi le oferă. Puteți găsi platforme VPS bune cu 1 & 1, TMDHosting, HostGator, Dreamhost și multe altele ... De asemenea, veți putea vedea caracteristicile VPS pe site-urile respective, împreună cu prețurile. Printre caracteristici veți vedea memoria RAM, procesoarele, stocarea disponibilă, lățimea de bandă sau traficul de rețea permis etc. În plus, aceste VPS-uri pot fi Linux sau Windows în principal, în funcție de nevoile dvs.
Pe de altă parte, avem alte servicii ceva mai avansate, cum ar fi cele din cloud, care ne permit contract IaaS (Infrastructură ca serviciu) sau infrastructură ca serviciu. Adică ne permite să avem un supercomputer sau un server ca serviciu fără a fi nevoie să îl avem fizic. În acest caz, avem Microsoft Azure, Google Cloud Platform, IBM SoftLayer, CloudSigma, Rackspace, VMWare vCloud Air, Amazon Web Services, Citrix Workspace Cloud, Oracle Cloud Infrastructure etc.
Fuentes:
Arhitectura computerului și microprocesorului - Lumea lui Bitman
Sisteme de operare și administrare - C2GL
Nu uitați să vă lăsați comentariile cu îndoieli, contribuții sau ceea ce ați găsit umila mea contribuție ... Sper că v-a ajutat să aflați mai multe despre această lume.
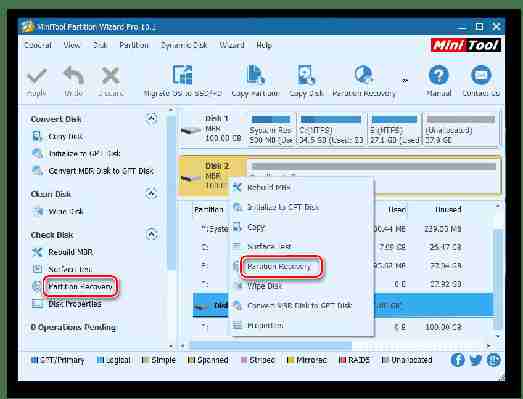
-
 December 25,2021
December 25,2021Cerințele de sistem Arbor...
-
 December 07,2021
December 07,2021Cum de a crește viteza In...
-
 December 04,2021
December 04,2021STUDIU: Industria de soft...
-
 December 28,2021
December 28,2021Care este cel mai puterni...
-
![Ethernet nu are o configurație IP validă în Windows 10 [Fix]](https://www.redgemcomputer.com/storage/upload/Images/76423be1dd323dac6e946cf30ab6752c.jpg) December 16,2021
December 16,2021Ethernet nu are o configu...
-
 December 19,2021
December 19,2021Programe utile pentru eva...
-
 December 10,2021
December 10,202115 cele mai bune procesoare...
-
 December 22,2021
December 22,2021Topul celor mai bune 4 softwar...
-
 December 13,2021
December 13,2021Mărire volum audio calcul...
-
December 28,2021
Care este cel mai puterni...
-
 December 01,2021
December 01,2021Placi si eroare? primire...
Post a Comment